Infrastructure following pedagogy: Focusing LLMs on a Structured & Embedded Curriculum
By shifting from vast, general training data to a "knowledge layer" of curated course content, a students LLM becomes a functional runtime. The educational value is decoupled from the llm and concentrated in the professor’s structured data, providing a focused, stable search space for students.

I have been thinking about friction.
Not the dramatic kind — not the moment a student gives up on a concept or drops the course. The small, accumulated kind. The invisible tax on learning that comes from context-switching: you are working on code or developing your course or performing some analysis (I'm switching from RStudio to Positron), running an R or python script, and something doesn't make sense.
You open a browser tab. You navigate to the course website, textbook, slides, or other resources relevant to what you are doing. You find the right module. You skim until you locate the relevant section. You hold onto that content in working memory while you switch back to the editor and apply it. You close the tab, or you don't—how many tabs are open on your browser?
It is probably thirty seconds. But thirty seconds of broken context, repeated across an entire semester of analysis & work, adds up to something real. This breaks your flow state. And this is the kind of friction I find most interesting to overcome, because it sits at the intersection of pedagogy and infrastructure — neither purely a teaching problem nor purely a technical one.
The solution I am deploying right now is based on a Model Context Protocol (MCP) server setup (think a set of connections to have your AI agent plug into my knowledge base) that is also integrated directly into our code editor. It could be Gemini, Ollama, ChatGPT, or other AI chatbot workflow, I’ll be having the students connect to Positron’s integrated chat interface. Students configure a quick JSON configuration block, I give them a connection key, and the book, slides, handouts, data sets, and all other resources for the course becomes a live chat textbook they can query without leaving their editor.
The assistant that already knows their code context also, now, knows the course content, exercises and activities.
Here's how the whole thing works.
A Learning Quanta Model
Before getting into the infrastructure, it's worth explaining how my course content is structured, because the architecture follows from the content model — not the other way around.
Every class I teach (Data Literacy, Population Genetics, etc.) is composed of a collection of learning modules. I keep these models on GitHub and provide the content (book, activities, homework, etc.) via HTML using GitHub Pages. It is a pretty low-friction setup and is versatile as I can mix-and-match learning modules as I make another course. Need this new class to get basic Markdown + spatial analysis? Just addd them in. I have over 50 learning modules in my teaching repository at this time.
A module is a self-contained entity, thematically organized around a single topic like Markdown, Raster Analysis, Ordination, Logistic Regression, etc. Each module consists of several components written in markdown:
- README.md: This file that outlines the impetus of the topic, Learning Objectives (I'm a big proponent of backward design), links to resources, slides, videos, chapter documents, cheat sheets, etc. This is essentially the copy-and-paste content I insert into our teaching CRM system for the students. I think of it like the module syllabus.
- narrative.qmd: A long-form textual narrative document that gives background, theory, application, and use of the topic being taught. This also becomes the chapter in the course textbook.
- slides.qmd: A set of slides that I use for teaching the module. I write these in markdown as well and provide them as HTML slides via GitHub pages. I generally keep my slides svelte. Garr Reynolds book, Presentation Zen: Simple Ideas on Presentation Design and Delivery made a huge impact on my teaching and presentation.
- video.md: A link to a pre-recorded lecture on this material. I try to not be the "talking head in front of slides" but give more interpretative discussion of the concepts and if there are some coding involved, I like to provide demonstrations of specific tasks (it is also good for the students to see the professors poor typing and bug creation abilities in real-time).
- in-class.md: The kind of things I teach often require analysis and I find that adopting a flipped-classroom. Having the narrative + potential video + pre-meeting reading allows the students have a foundational grasp on the topic. During the short amount of time we have in class, there are active "doing" rather than "listen to a professor go over slides."
- assessment.qmd & assessment_key.qmd: An assessment tool, built from the module learning objectives, covering the content. I also have a key for each, that I make available to the students right after the assessment is due.
- auxiliary documents: Each module is buttressed by additional files and content. This may include data sets (or links to them), code examples, library cheatsheets (R does a great job at making summary documents for popular libraries), and other documentation. These are typically served as Title + Short description + link.
Whereas a narrative document, a set of slides, library documentation, data sets, manuscripts, and other components can be thought of as a set of vertical documents with sequentially delivered information. However, we can also decompose the content, semantically and logistically, into an ordered sequence of individual components. For example, my section on Basic Linear Regression consists of the following sections (literally the H2 headers of the narrative document):
- Background
- The Philosophy of Least Squares
- Fitting a Linear Model
- Model Fit and Sufficiency
- Extending Linear Models
- Model Comparisons
Each of these builds on the previous, is a mix of narrative + code + examples + graphics, selected slides, data sets, components of the video, in-class and assessment documents, etc. For simplicity, I call Learning Quanta (LQ), they are not atomic (in the PKM & Zettlekasten context) but collectively allow the module itself to be atomic.
A Learning Quantum is not a page or a chapter — it is the smallest piece of course content that can stand in sequence, the collection of which reconstitute the entirely of the modules content. Each LQ components, I refer to them as facets, contain the narrative (explained in prose) and all the subset of the remaining content that maps, conceptually, onto that narrative: slides, video, data sets, assessment, and all auxiliary documents. The narrative facet defines the pedagogical context and the remaining components are in support of it.
The goal here is to structure the LQ model around four questions that travel together:
- What is this concept? → the narrative facet
- How do I apply it in practice? → the code, video, and activity facets
- How do I communicate about it? → the slides, external documents, and homework facets
- How do we assess learning? → the components of the assessment tools used to evaluate the learning.
For ENVS543 Environmental Data Literacy, I have 15 modules and when they are decomposed into their own canonical LQ, I have 76 LQs. Semantically, they cover the full arc of instruction, background, data, and evaluation on topics starting with basic R data types through statistical and spatial analysis, all within the context of building student efficiency at skills that promote reproducible research.
Exposing Your LQs
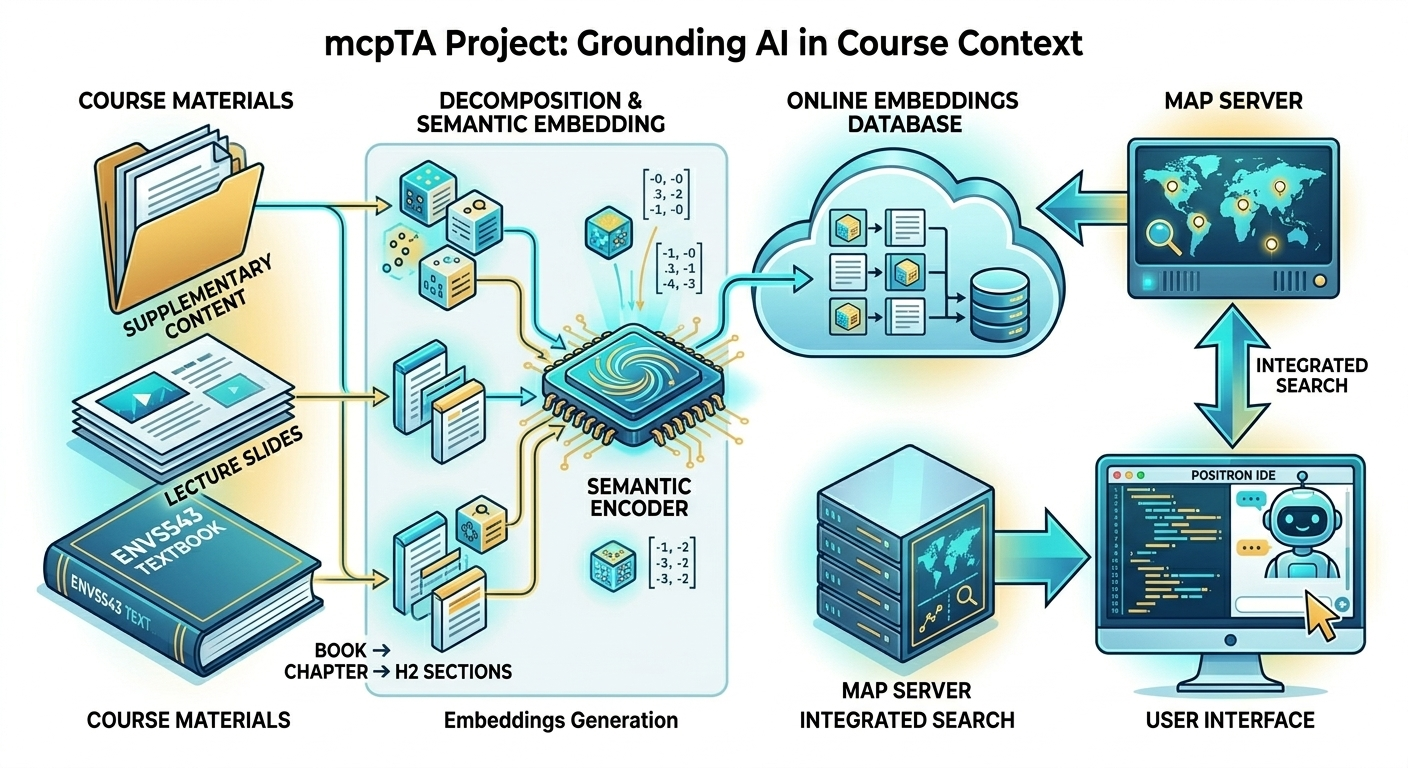
The content of each facet in an LQ is then mapped onto a semantic space. I’m using OpenAI’s text-embedding-small model, which maps textual content into a 1536 dimensional ”semantic” space. I think of this as giving a bit of text/code/slide content a unique coordinate in a high-dimensional space. This is essentially how modern LLM's map meaning from text.
Each facet is a discrete, queryable piece of content, and the collection of facets in a module defines a de facto point cloud in a discrete region of semantic space. We can think of the LQ as a convex hull (e.g. think of a region in this semantic space whose boundaries are defined by the points themselves—like the shape a rubber band would make when wrapped around all the points on a 2-dimensional x, y plot). Semantically, the complete content of the LQ is contained within this point cloud.
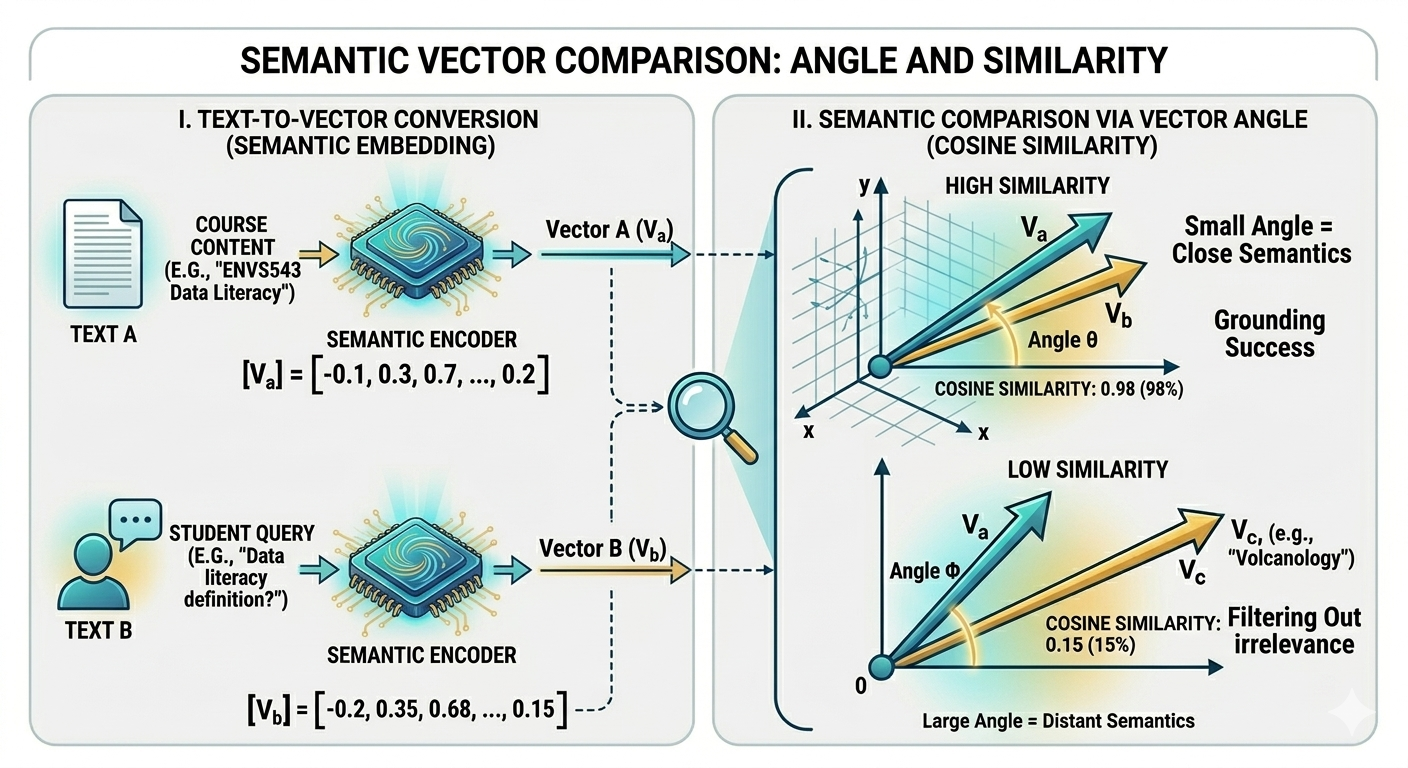
This is key because when a student submits a query through their LLM agent, the text of your query is embedded in this same space and then it looks for embedded content that is ‘in the region’ of your query. This is why, sometimes, you need to ask a slightly longer question to get the right answer from an LLM—context matters.
Perhaps more importantly, the entirety of the teaching content I provide defines a much more limited search space for the LLM. Without it, the LLM attempts to find answers from semantic space built from its complete knowledge set. While training data for these LLMs are huge, they are not focused on course content. With focused semantic spaces, the LLM becomes simple infrastructure. A student using Positron with your MCP server isn’t getting value from Claude, ChatGPT, or from whatever model Positron ships with next year. They’re getting value from the 76 LQs that the professor wrote, structured, and embedded. Swap the model out entirely — the value doesn’t move. The knowledge stays.
The knowledge layer created by embedding all course content is where the educational value concentrates, and the LLM model is just the runtime that executes against it.
This is not incidental to the system I built — it is the reason the system can be built at all.
Overview of the mcpTA Stack
For this stack to work, there needed to be a few layers. To create the content, I started with the raw Quarto—markdown—that I use to write narratives, slides, exams, code, etc.
The full narrative was decomposed into LQ’s. The set of slides (another markdown. Document) is then pulled apart and individual slides were mapped onto their corresponding LQ narrative. Same for all other content (in-class activities, homework, etc.).
Quarto .qmd files (GitHub)
↓ ingest_narrative.ts (Deno)
Supabase (PostgreSQL + pgvector)
↓ dyerlab-teach Edge Functions (Deno + Hono)
Positron AI Assistant (MCP client)
We then set up an online database. I use PostgreSQL because it is also useful for geospatial data but it could be replaced with another db layer if necessary. I defined table schema for LQ’s, module mappings, facets, etc. and the textual content of each is embedded in semantic space. Supabase is an online database provider that makes available an instance of its PostgreSQL database with the pgvector extension (for the semantic embedding and coordinated vector operations) for projects like this. I used it because it is easy and available.
Next, I developed some edge functions in python that serve as an intermediary between the database structure itself and the open channels that the LLM models will use. The MCP SDK handles the protocol layer and I hook it up to OpenRouter so it can handle the embedding activities on the fly. So, when the student submits a query, it goes through OpenRouter for embedding and then the edge functions in Supabase take query against the embedded content database and return content (or not).
Nothing here is exotic. The interesting part is how they fit together.
The Database Schema
In the database, it is pretty straight forward, only four tables.
lqs -- one row per Learning Quantum
lq_facets -- content atoms (narrative, slides, code, activity, homework)
modules -- named, ordered sequences of LQ references
module_lq_sequence -- join: (module, lq, position)
A few design decisions worth naming:
- LQs are globally scoped, not deduplicated. For example the concept of "Missing Data" appears in both the Data Containers module and the Statistics module. They are taught differently, for different audiences, in different contexts. Each gets its own row in
lqs, identified by(title, source_module). Semantic similarity across them emerges from the embedding layer — I'm not forcing it at the schema level, which would just flatten information I want to preserve. - Content lives in
lq_facets, not inlqs. Thelqstable is a registry and a semantic index. The actual markdown content — the prose, the code, the slides — lives inlq_facets.content, with one row per facet type per LQ. This keepslqslean and makes adding new facet types later a non-event. It also means I can ask "what are all the code facets for the Tidyverse module?" as a simple filter query, which turns out to be exactly what I need. - Embeddings at two levels. Each
lq_facetsrow has its ownvector(1536)embedding. Thelqs.embeddingis the mean of all its facet embeddings — a semantic barycenter of the whole concept (the center of the convex hull mentioned above). This mirrors something I've been thinking about in a different project (the Nooscope treatment of MOC notes as barycenters of their constituent notes), and it works for the same geometric reason: if each facet is a vector in semantic space, the mean gives you a point that is "near" all of them without being identical to any. Recently, I’ve been using these notions of semantic overlap and temporal ordering of teaching content to as a more sophisticated way to conceptualize course structure—developing taxonomies that would be able to differentiate between Linear Pedagogy (a list of topics) to Topological Pedagogy (volumes of meaning). A colleague and I are working on applying these ideas to full academic curricula. - Content hashes for idempotency. One last thing. The raw content is not static. I go in an add to (often spell check…) and change my teaching content. So each
lq_facetsrow stores a SHA-256 hash of its content So that on rescan, we can tell if it had chaneed since last import (then update it) or not (ignore). So as the textual basis of my modules evolve, the semantic representation can be kept up-to-date. In fact, if GitHub were to go away, the db structure could be used to faithfully reconstruct the entirety of the teaching materials. Re-running the ingest pipeline after a small edit only re-embeds what actually changed. This matters when you have 76 LQs and revise one sentence in Module 4 at 11pm before a class.
The Ingest Pipeline
For the injection of the raw content, I have a Deno script — ingest_narrative.ts — parses each module's narrative.qmd file and loads it into the database:
- Strip YAML frontmatter
- Split on
##boundaries, tracking code fence state to avoid treating R's##comment syntax as a section break - Hard-reject any section exceeding the embedding context window (~32,000 chars). Perhaps not surprisingly, my writing style has H2-level breaks below this chunk size.
- Upsert the module record from
README.mdwhich on my GitHub Page has the modules impetus, learning objectives, and links to narratives, slides, data sets, cheatsheets, etc. So each module object knows where the human readable components are being served from and the LLM model can pass that along to the student as necessary. - Upsert each LQ and its narrative facet
- Write position to
module_lq_sequence.I’m toying with the notion of on-the-fly content creation so there has to be an ordering of LQs.
The central design rule is worth stating directly: hard-reject on any structural deviation. No silent fixes, no algorithmic repair. If a section is malformed, the scripts exit with a clear error message and a non-zero status code. The reason for this is cross-facet alignment — if the narrative parser splits content differently from the slides parser, the LQ structure breaks and semantic search returns incoherent results. Failing loudly is the only responsible behavior.
Running across all 15 modules is fast and easy.
✓ Analysis-of-Variance (3 LQs)
✓ Basic-Data-Types (5 LQs)
...
✓ Tidyverse (3 LQs)
76 facets embedded, 76 LQ mean embeddings updated.
The next step is to decorate the LQs with remaining facet components. For this, I use a local agent. I run Ollama locally and does a good job at small tasks like this. In my workflow, there are several independent agents that have specific rules and if possible, I prefer to run them locally and have developed a library to optimize local model selection that is optimized for MacOS hardware (see my Linguistics package).
The MCP Server
As I outlined, the server is a Supabase Edge Function — about 200 lines of Deno TypeScript using Hono for routing and the MCP SDK for the protocol layer. It exposes four tools:
search_content | Semantic search across all LQ facets; filter by module or facet type |
get_lq | Full content of a specific LQ with all facets |
list_modules | All modules with LQ counts |
get_module_sequence | Ordered LQs for a module |
Auth is a shared x-teach-key header — one key per semester, distributed to the class. It rotates each semester. Students can read; no one can write through the MCP interface.
Deploying is one command:
supabase functions deploy dyerlab-teach --no-verify-jwt
That's the entire deployment surface. No servers to manage, no containers to orchestrate. Supabase runs the function at the edge, pgvector handles the similarity search, and the whole thing costs roughly nothing at course-enrollment scale. We just provide the pipes and content layer for the LLM to interface with.
What Students Actually Experience
Students add one block to their Positron settings.json — the configuration file Positron already uses for editor preferences:
"mcp.servers": {
"dyerlab-teach": {
"type": "http",
"url": "https://<project>.supabase.co/functions/v1/dyerlab-teach",
"headers": {
"x-teach-key": "envs543-fall-2026",
"apikey": "<publishable-key>"
}
}
}
That's the entire student-facing setup. One JSON block, one restart, and the course is live inside the assistant.
After that, a student writing an R script can ask the assistant in natural language:
- "How do I test for equal variance before running an ANOVA?"
- “Describe that atmospheric data we were working on from the Rice Rivers Center.”
- "Show me the correlation module sequence."
- "What's the difference between
left_joinandinner_join?" - "I need a permutation test — do we cover that?"
Instead of a generic LLM response, the assistant calls search_content, retrieves the relevant LQ facets from the actual course material, and grounds its answer in the text the student is already supposed to be reading. The course website doesn't disappear — but the reason to leave the editor for a quick conceptual question largely does.
The AI assistant already knows what the student is writing. Now it also knows what the course says about it.
This is the friction reduction I was after. Not a clever interface, not a chatbot bolted onto a LMS. Just the course content, properly indexed, accessible from inside the tool where the work actually happens.
What's Next
- GitHub Actions for continuous re-ingest. Right now, re-running the pipeline is a manual step. Wiring it to a push event on the course content repo means the MCP server is always current with the latest version of every module. This is the natural end state: the database as a living index, not a snapshot.
- Code Switching. I’d like to inject some code language conversions into the system that would allow the students to specify ‘python’ or ‘Julia’ and have the code translated on the fly. I’m not sure we are at parity between languages for the kinds of things I teach across all domains, and there may be some ingestion-side activities that may need to take place.
The longer arc is a conceptual inversion I find genuinely interesting: instead of modules as the source of truth that get ingested into a database, the database becomes the source of truth from which modules are assembled. The LQ becomes the unit of composition, and the narrative .qmd files are one rendering of it among several potential ones—but that is a longer project.
On the Broader Point
There is a version of this post that is purely technical — database schema, ingest pipeline, MCP server, configuration — and the draft I wrote first was more or less that post. I scrapped it because the technical choices are not the interesting part.
The interesting part is the pedagogical claim embedded in the architecture: that the course content should be available where the work happens, not where the instructor put it. I structured ENVS543 around Learning Quanta because I believe instruction works best when content is atomic, addressable, and cross-referenceable. The MCP server is the same belief applied to delivery. If the LQ is the right unit for structuring knowledge, it is also the right unit for retrieving it.
The infrastructure follows from the pedagogy. That's the direction of causation I care about.
The full pipeline lives in the mcpTA repo. Student setup instructions are in the course documentation. Happy to discuss any part of the stack.
Happy coding!